Jan V1 Setup Guide
jan-v1mcpsearch
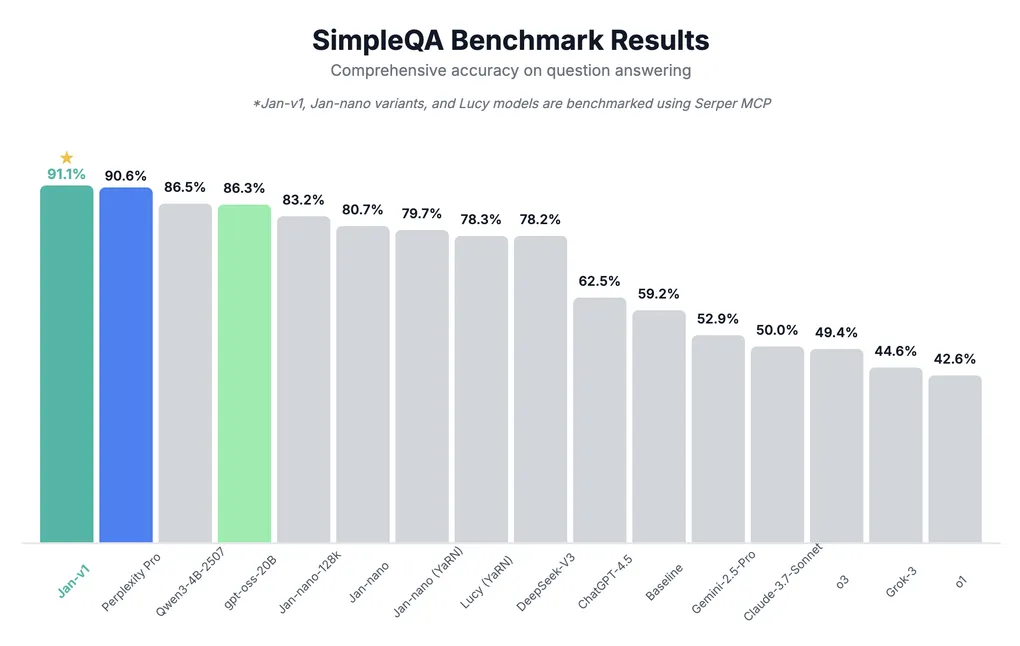
What is Jan V1?
Jan V1 is a 4B parameters language model that achieves 91.1% accuracy on SimpleQA through reinforcement learning with verifiable rewards (RLVR). It’s optimized for searching and synthesizing information from the internet.
This guide covers the basic setup and usage of Jan V1.
System Requirements
- Memory: Minimum 8GB RAM (Q4 quantization), Recommended 16GB RAM (Q8 quantization)
- Hardware: CPU or GPU
- Storage: 2.5GB - 4.28GB depending on quantization level
Basic Usage with Jan Desktop
- Download latest version of Jan Desktop from jan.ai
- Install and launch the application
- Select and download Jan V1 from the model list. Q8_0 is recommended for best performance.
- Start chatting - no additional configuration needed!
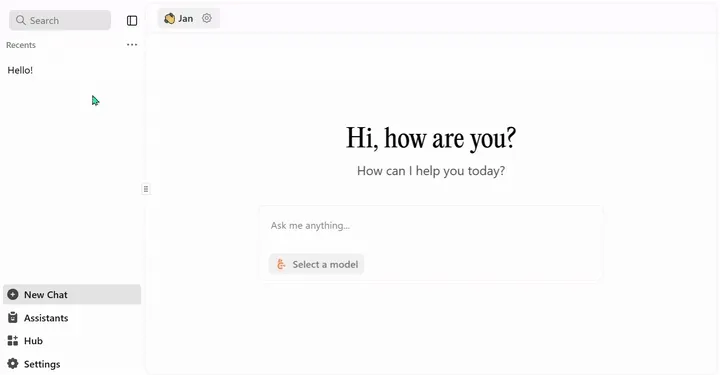
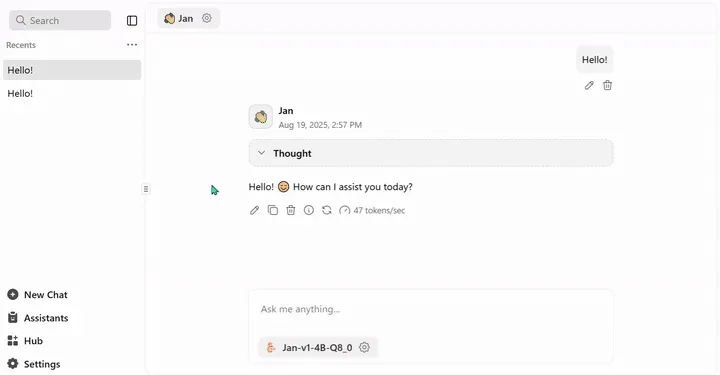
Search Setup
To enable search capabilities in Jan Desktop:
- Ensure you are using the latest version of Jan Desktop that supports MCP (0.6.8 or higher)
- Go to Settings → General → Experimental Features → On
- Go to Settings → MCP Servers → enable Search-related MCP (e.g., Serper)
- Enter your Serper API key in the MCP Servers settings. You can get your API key here
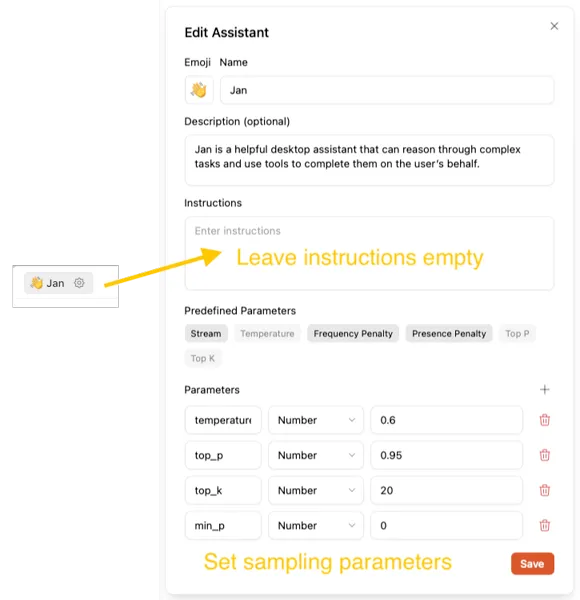
- Ensure Jan’s instruction field is empty and use recommended sampling parameters. Jan v1 comes with baked instructions, so you need to remove any custom instructions in Jan Assistant to use the Jan v1 model at its best performance.
- After that, you can choose Jan V1 as your model and start using search capabilities in Jan!
Available Quantizations
Choose based on your memory constraints:
- Q4_K_M: 2.5 GB - Good balance of size and quality
- Q5_K_M: 2.89 GB - Better quality, slightly larger
- Q6_K: 3.31 GB - Near-full quality
- Q8_0: 4.28 GB - Highest quality quantization (recommended for best performance)
Recommended Setting
- temperature: 0.6
- top_p: 0.95
- top_k: 20
- min_p: 0.0
Server Setup
vLLM
For vLLM, the model is baked with the recommended sampling parameters and a system prompt by default to match benchmark performance so you don’t need to set it manually.
vllm serve janhq/Jan-v1-4B \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--reasoning-parser qwen3llama.cpp
- Install llama.cpp following the instructions here
- Download
Jan-v1-4B-Q8_0.gguffrom Hugging Face - Run the following command:
llama-server --model path/to/Jan-v1-4B-Q8_0.gguf \
--host 0.0.0.0 \
--port 1234 \
--jinja \
--no-context-shiftConnect Jan with Jan-V1 Server
If using vLLM or llama.cpp, the model will be available at:
- Endpoint:
http://localhost:1234/v1 - API Format: OpenAI-compatible
This can be easily connected to the Jan application
Troubleshooting
- Out of Memory: Try a lower quantization level (Q4 instead of Q8)
- Slow Performance: Ensure adequate RAM and consider GPU acceleration
- Model Not Loading: Verify file paths and permissions
- API Connection: Check if the server is running on the correct port
- Infinite Loop: Try to use the largest quantization level (Q8)
- Missing MCP Section: Ensure you are using the latest version of Jan Desktop that supports MCP (0.6.8 or higher) and enable Experimental Features
- Error 403 when using search: Ensure you have entered your Serper API key in the MCP Servers settings. You can get your API key here